
At Autohost, we care about making data-driven decisions. I know many companies say this, but we mean it. We have a lot of data, and we want to use it to make better decisions. One of the issues is related to understanding the differences between signed contracts and billed invoices, and how to predict revenue. We can't tell if we are on track to hit our revenue goals, because we don't know how much revenue we will get from our existing customers as product usage changes.
In this article I will show you how we connected our Hubspot CRM to our data warehouse, and how we use this data to predict revenue.
The Tech Stack
- Hubspot is a great CRM for startups, and it has all the features you need to manage your sales pipeline.
- AWS Glue is a serverless ETL service that we use to create specialized datasets for our data warehouse.
- AWS Quicksight is a serverless Business Intelligence tool that we use to visualize our data.
- AWS Lambda is a serverless compute service that we use to run the HubSpot export script.
Solution Overview
- Export
deals,companies, andcontactsfrom HubSpot on a scheduled basis. - Upload each export to an S3 bucket.
- Use AWS Glue Crawler to create a table for each export.
- Use QuickSight to import the datasets, combine other tables, and visualize the data.
Exporting Data from HubSpot
Start a new Node.js project, and install the dependencies.
mkdir hubspot-export
cd hubspot-export
npm init -y
npm install --save @hubspot/api-client
npm install --save-dev aws-sdk serverless serverless-bundle serverless-offline
We are using the following libraries:
- @hubspot/api-client is the official HubSpot API client.
- aws-sdk is the official AWS SDK.
- serverless is a framework for building serverless applications.
- serverless-bundle is a plugin for serverless that bundles your code.
- serverless-offline is a plugin for serverless that allows you to run your code locally.
Create a serverless.yml file with the following contents:
service: hubspot-connector
provider:
name: aws
runtime: nodejs16.x
architecture: arm64
stage: ${opt:stage, 'prod'}
region: us-east-1
timeout: 900
memorySize: 2048
logRetentionInDays: 7
versionFunctions: false
environment:
STAGE_NAME: dev
REGION: ${self:provider.region}
HUBSPOT_API_KEY: ENTER_YOUR_HUBSPOT_API_KEY_HERE
S3_BUCKET: hubspot-connector-${aws:accountId}-${self:provider.region}
iamRoleStatements:
- Effect: Allow
Action:
- s3:PutObject
- s3:GetObject
Resource:
- arn:aws:s3:::hubspot-connector-${aws:accountId}-${self:provider.region}/datalake/hubspot/*
functions:
scheduledHubspotExport:
handler: handler.scheduledHubspotSync
events:
- schedule:
# run every sunday at 1am
rate: cron(0 1 ? * SUN *)
enabled: true
plugins:
- serverless-bundle
- serverless-offline
resources:
Description: "Autohost CRM Connector for HubSpot"
Resources:
PrimaryBucket:
Type: AWS::S3::Bucket
Properties:
BucketName: hubspot-connector-${aws:accountId}-${self:provider.region}
AccessControl: Private
BucketEncryption:
ServerSideEncryptionConfiguration:
- ServerSideEncryptionByDefault:
SSEAlgorithm: AES256
This file defines the following:
providerdefines the AWS provider, and sets some defaults.functionsdefines thescheduledHubspotExportfunction, which will be triggered on a schedule.pluginsdefines the plugins we are using.resourcesdefines the CloudFormation resources that will be created.iamRoleStatementsdefines the IAM permissions that the function will have.environmentdefines the environment variables that the function will have.eventsdefines the schedule for the function.
Create a handler.js file with the following contents:
import {Client} from "@hubspot/api-client";
import AWS from "aws-sdk";
const notEmpty = value => Boolean(value && typeof value !== 'undefined' && value !== '' && value !== null);
const putObject = async (key, body, contentType) => {
const s3 = new AWS.S3();
const params = {
Bucket: process.env.S3_BUCKET,
Key: key,
Body: body,
ContentType: contentType,
};
return await s3.putObject(params).promise();
};
export const scheduledHubspotSync = async (event, context) => {
const objects = [
// 'contacts',
'companies',
'deals',
];
for (const object of objects) {
console.log(`Starting to sync ${object} from Hubspot`);
const list = await getHubspotObjects(object);
const data = list.map(obj => JSON.stringify(obj)).join('\n');
await putObject(`datalake/hubspot/${object}/export.json`, data, 'text/plain');
console.log(`Uploaded ${list.length} ${object} to S3`);
}
};
const getHubspotClient = async () => {
return new Client({accessToken: process.env.HUBSPOT_API_KEY});
};
const getHubspotProperties = async (objectName) => {
const client = await getHubspotClient();
return await client.crm.properties.coreApi.getAll(objectName);
};
const getHubspotPipelinesMap = async () => {
const output = {};
const client = await getHubspotClient();
const pipelines = await client.crm.pipelines.pipelinesApi.getAll('deals');
for (const pipeline of pipelines.results) {
// add pipeline to output
output[pipeline.id] = {
id: pipeline.id,
label: pipeline.label,
stages: [],
};
// add stages to output
const pipelineStages = await client.crm.pipelines.pipelineStagesApi.getAll('deals', pipeline.id);
for (const stage of pipelineStages.results) {
output[pipeline.id].stages.push({
id: stage.id,
label: stage.label,
});
}
}
return output;
};
const getHubspotOwnersMap = async () => {
const output = {};
const client = await getHubspotClient();
// get owners in pages
let after;
while (true) {
const owners = await client.crm.owners.ownersApi.getPage(after);
// add owners to output
for (const owner of owners.results) {
output[owner.id] = {
id: owner.id,
email: owner.email,
first_name: owner.firstName,
last_name: owner.lastName,
name: [owner.firstName, owner.lastName].filter(n => n && n !== '').join(' '),
teams: (owner.teams || []).map(team => ({
id: team.id,
name: team.name,
}))
};
}
// break if there are no more pages
if (!owners.paging || !owners.paging.next || !owners.paging.next.after) {
break;
}
// get the next page
after = owners.paging.next.after;
}
return output;
};
const formatContacts = async (data) => {
const contacts = data.map(contact => {
// format contact
const obj = {
id: contact.id,
created_at: new Date(contact.createdAt).toISOString(),
updated_at: new Date(contact.updatedAt).toISOString(),
archived: contact.archived,
contact_company_id: null,
contact_deal_id: null,
email: contact.properties.email,
first_name: contact.properties.firstname,
last_name: contact.properties.lastname,
};
// format dates
Object.keys(obj).forEach(key => {
if (key.includes('date') && notEmpty(obj[key]) && obj[key].length > 10) {
try {
obj[key] = new Date(obj[key]).toISOString();
} catch (error) {
console.warn(`Error formatting date field '${key}' for contact ${contact.id}: ${error}`);
}
}
});
// add associations
if (contact.associations) {
if (contact.associations.companies && contact.associations.companies.results.length > 0) {
obj.contact_company_id = contact.associations.companies.results[0].id;
}
if (contact.associations.deals && contact.associations.deals.results.length > 0) {
obj.contact_deal_id = contact.associations.deals.results[0].id;
}
}
return obj;
});
return contacts;
};
const formatCompanies = async (data) => {
// get owners
const owners = await getHubspotOwnersMap();
// format companies
const companies = data.map(company => {
const obj = {
id: company.id,
created_at: new Date(company.createdAt).toISOString(),
updated_at: new Date(company.updatedAt).toISOString(),
archived: company.archived,
company_contact_id: null,
company_deal_id: null,
...company.properties,
};
// format dates
Object.keys(obj).forEach(key => {
if (key.includes('date') && notEmpty(obj[key]) && obj[key].length > 10) {
try {
obj[key] = new Date(obj[key]).toISOString();
} catch (error) {
console.warn(`Error formatting date field '${key}' for company ${company.id}: ${error}`);
}
}
});
// add associations
if (company.associations) {
if (company.associations.contacts && company.associations.contacts.results.length > 0) {
obj.company_contact_id = company.associations.contacts.results[0].id;
obj.company_contact_ids = [...new Set(company.associations.contacts.results.map(c => c.id))];
}
if (company.associations.deals && company.associations.deals.results.length > 0) {
obj.company_deal_id = company.associations.deals.results[0].id;
obj.company_deal_ids = [...new Set(company.associations.deals.results.map(d => d.id))];
}
}
// replace owner ids with labels
if (obj.hubspot_owner_id) {
obj.company_hubspot_owner = owners[obj.hubspot_owner_id] ? owners[obj.hubspot_owner_id].name : `Deleted user (${obj.hubspot_owner_id})`;
}
return obj;
});
return companies;
};
const formatDeals = async (data) => {
// get pipelines
const pipelines = await getHubspotPipelinesMap();
// get owners
const owners = await getHubspotOwnersMap();
// format each deal object
const deals = data.map(deal => {
// format deal
const obj = {
id: deal.id,
created_at: new Date(deal.createdAt).toISOString(),
updated_at: new Date(deal.updatedAt).toISOString(),
archived: deal.archived,
deal_contact_id: null,
deal_company_id: null,
...deal.properties,
};
// format dates
Object.keys(obj).forEach(key => {
if (key.includes('date') && notEmpty(obj[key]) && obj[key].length > 10) {
try {
obj[key] = new Date(obj[key]).toISOString();
} catch (error) {
console.warn(`Error formatting date field '${key}' for deal ${deal.id}: ${error}`);
}
}
});
// add associations
if (deal.associations) {
if (deal.associations.contacts && deal.associations.contacts.results.length > 0) {
obj.deal_contact_id = deal.associations.contacts.results[0].id;
obj.deal_contact_ids = [...new Set(deal.associations.contacts.results.map(c => c.id))];
}
if (deal.associations.companies && deal.associations.companies.results.length > 0) {
obj.deal_company_id = deal.associations.companies.results[0].id;
}
}
// replace pipeline and stage ids with labels
if (obj.pipeline) {
if (obj.dealstage && pipelines[obj.pipeline]) {
obj.deal_dealstage = pipelines[obj.pipeline].stages.find(s => s.id === obj.dealstage).label;
}
obj.deal_pipeline = pipelines[obj.pipeline] ? pipelines[obj.pipeline].label : obj.pipeline;
}
// replace owner ids with labels
if (obj.hubspot_owner_id) {
obj.deal_hubspot_owner = owners[obj.hubspot_owner_id] ? owners[obj.hubspot_owner_id].name : `Deleted user (${obj.hubspot_owner_id})`;
}
return obj;
});
return deals;
};
const getHubspotObjects = async (objectName) => {
// initialize the client
const client = await getHubspotClient();
// get the list of properties for the object and filter out the ones we don't want
const fields = await getHubspotProperties(objectName);
console.log(`Found ${fields.results.length} properties for ${objectName}`);
const properties = fields.results
.map(field => field.name)
.filter(name => !name.includes('hs_date'))
.filter(name => !name.includes('hs_time'))
.filter(name => !name.includes('hs_v2_date'))
.filter(name => !name.includes('hs_v2_cumulative_'))
.filter(name => !name.includes('hs_v2_lastest_time'))
.filter(name => !['createdate', 'lastmodifieddate', 'hs_lastmodifieddate'].includes(name));
console.log(`Using ${properties.length} properties for ${objectName}`);
// create a list of associations to include
const associations = [];
if (objectName === 'contacts') {
associations.push('companies');
associations.push('deals');
} else if (objectName === 'companies') {
associations.push('contacts');
associations.push('deals');
} else if (objectName === 'deals') {
associations.push('contacts');
associations.push('companies');
}
// get the list of objects
const results = await client.crm[objectName].getAll(
100,
0,
properties,
[],
associations
);
// format the results
switch (objectName) {
case 'contacts':
return await formatContacts(results);
case 'companies':
return await formatCompanies(results);
case 'deals':
return await formatDeals(results);
default:
return results;
}
};
This file defines the following:
scheduledHubspotSyncis the function that will be triggered on a schedule.getHubspotObjectsis a function that gets a list of objects from HubSpot.formatContactsis a function that formats a list of contacts.formatCompaniesis a function that formats a list of companies.formatDealsis a function that formats a list of deals.getHubspotPropertiesis a function that gets the list of properties for an object.getHubspotPipelinesMapis a function that gets the list of pipelines for deals.getHubspotOwnersMapis a function that gets the list of owners.putObjectis a function that uploads an object to S3.notEmptyis a function that checks if a value is not empty.
That's pretty much it for the code. Now we need to configure the HubSpot API key and the S3 bucket.
- In your HubSpot account, click the settings icon in the main navigation bar.
- In the left sidebar menu, navigate to Integrations > Private Apps.
- Click Create private app.
- On the Basic Info tab, configure the details of your app:
- Enter your app's name.
- Hover over the placeholder logo and click the upload icon to upload a square image that will serve as the logo for your app.
- Enter a description for your app.
- Click the Scopes tab.
- In the CRM section, select the following scopes:
- Contacts - Read
- Companies - Read
- Deals - Read
- Owners - Read
- Pipelines - Read
- Pipeline Stages - Read
- After you're done configuring your app, click Create app in the top right.
- In the dialog box, review the info about your app's access token, then click Continue creating.
You can view the full documentation here.
Enter the API key in the serverless.yml file.
HUBSPOT_API_KEY: ENTER_YOUR_HUBSPOT_API_KEY_HERE
Now we need to deploy the serverless stack.
npx serverless deploy --verbose
This will create the following resources:
- An S3 bucket for storing the data.
- An IAM role for the Lambda function.
- A Lambda function that will be triggered on a schedule.
- A CloudWatch event that will trigger the Lambda function on a schedule.
- A CloudWatch log group for the Lambda function.
To remove the stack, run the following command:
npx serverless remove --verbose
Creating Tables in AWS Glue
Now that we have the data in S3, we need to create tables in AWS Glue Catalog. This will allow us to query the data using SQL in Athena, or visualize the data using QuickSight.
- In the AWS Console, navigate to AWS Glue.
- In the left sidebar menu, click Crawlers.
- Click Add crawler.
- Enter a name for the crawler (e.g.
hubspot-crawler-deals). - Click Next.
- Select Data stores.
- Select S3.
- Enter the path to the data (e.g.
s3://hubspot-connector-123456789012-us-east-1/datalake/hubspot/deals/). - Click Next.
- Select Create an IAM role.
- Enter a name for the role (e.g.
glue-crawler-role). - Click Next.
- Select Run on demand (you can schedule the crawler later).
- Click Next.
- Click Add database.
- Enter a name for the database (e.g.
hubspot). - Click Create.
- Click Next.
- Click Finish.
This will create a crawler that will create a table for the deals data. You can repeat this process for the companies and contacts data.
Now we need to run the crawler. Wait for the crawler to finish running, and then click on the crawler name. You should see the new table in the Tables section. This is good enough for querying the data using Athena or QuickSight.
Using QuickSight
Now that we have the data schema in the AWS Glue Catalog, we can import the data into QuickSight.
- In the AWS Console, navigate to QuickSight.
- In the left sidebar menu, click Manage data.
- Click New data set.
- Click Athena.
- Enter a name for the data source (e.g.
Athena). - Click Create data source.
- Select the database (e.g.
hubspot). - Select the table (e.g.
deals). - Click Select.
- Click Edit/Preview data.
- Click Save & visualize.
This will create a new dataset in QuickSight that you can use to create visualizations.
A single table is not very useful, so we need to join the tables together.
- Go back to the QuickSight home page.
- Click on Datasets.
- Click on the dataset you created.
- Click on Edit Dataset.
- In the editor, click on the
Add databutton. - Select
Data sourceand choose theAthenadata source. - Select the
hubspotdatabase. - Select the
companiestable. - Click on the
Selectbutton.
This will add the companies table to the dataset.
Now we must join the tables together.
- Click on the two overlapping circles icon.
- In the "Join configuration" section, select the
Leftjoin type. - Select the
deal_company_idfield in thedealstable. - Select the
idfield in thecompaniestable. - Click on the
Applybutton.
This will join the deals and companies tables together.
Now you can visualize your HubSpot deals data in QuickSight.
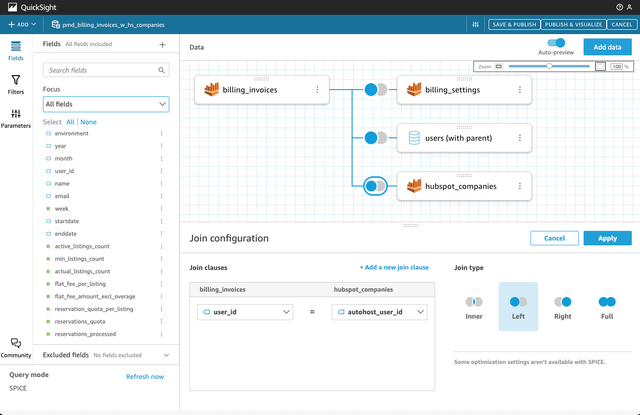
At Autohost, our RevOps team joined our HubSpot data together with our invoices, billing settings, user accounts, and product usage data. This allows us to predict revenue, and make data-driven decisions. We can investigate discrepancies between signed contracts and billed invoices, and we can predict revenue based on product usage.
We created a custom property in HubSpot on deals and companies called autohost_user_id to help us link between HubSpot and the users in our product.
The onboarding team updates this property after deals are closed, during the onboarding process.