Smart Documentation: Leveraging AI to Build a Dynamic Knowledge Base

Imagine a world where your product documentation updates itself, always staying fresh and relevant. A world where customer support tickets automatically transform into valuable knowledge resources. Sound like science fiction? Not anymore.
In the fast-paced realm of customer support, keeping documentation up-to-date can feel like a never-ending battle. But what if we could harness the power of AI to turn this challenge into an opportunity?
A few weeks ago, my VP of Support and Customer Success approached me with an intriguing question: How can we utilize cutting-edge AI technology to create product documentation from the wealth of information hidden in our support tickets? Their quarterly project to update our knowledge base was looming, and they were looking for a way to automate the process, save time, and ensure our documentation always reflected the latest customer needs.
This sparked an exciting journey into the world of AI-powered documentation. In this article, I'll take you step-by-step through the process of building a system that uses Large Language Models (LLMs) to transform HubSpot support tickets into a dynamic, ever-evolving knowledge base.
Get ready to revolutionize your documentation process. Let's dive in!
The total cost of this project ended up being around $90 for 2100 support tickets, which was well worth it considering the time and resources saved. The team was able to focus on more important tasks, and the knowledge base was updated with the latest information from support tickets.
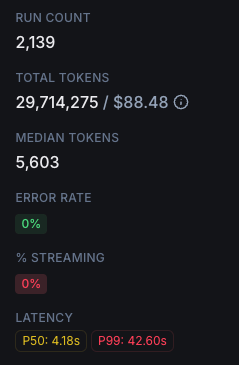
Architecture
The project requirements were to create a system that can:
- Use existing documentation categories
- Automatically categorize support tickets
- Generate unique FAQ articles from the tickets
- Keep count of the number of times a question is asked to prioritize the most common questions
After some thinking, I came up with the following architecture:
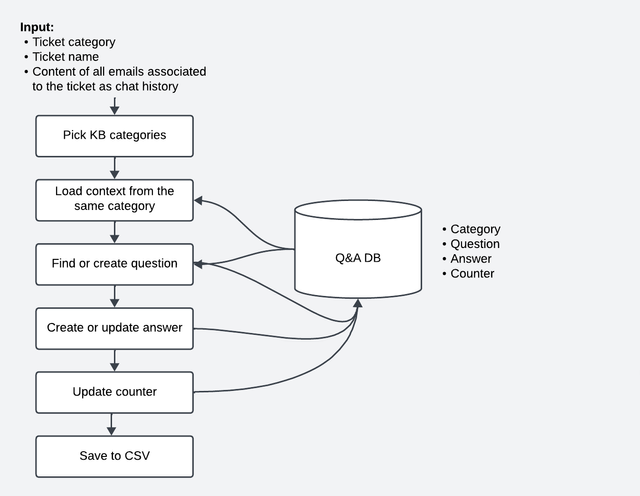
For each support ticket, the system will:
- Categorize the ticket based on existing documentation categories.
- Load additional context, such as associated emails from HubSpot.
- Find a matching FAQ question in our temporary database, or create a new one.
- Create or update the article to the FAQ question.
- Save the article and update the counter for the question in the database.
Let's dive into the implementation details.
You can skip the article and go directly to the GitHub repository for the full code and instructions.
Prerequisites
Before we begin, make sure you have the following prerequisites:
Let's Write Some Code
Step 1: Project Setup
Create a new directory for your project and initialize a new Node.js project:
mkdir hubspot-tickets-to-kb-docs
cd hubspot-tickets-to-kb-docs
npm init -y
mkdir src
Install the required packages:
npm install --save langchain @langchain/core @langchain/anthropic @fast-csv/parse @hubspot/api-client zod dotenv
Create a .env file in the project root and add your API keys:
echo "ANTHROPIC_API_KEY=your_api_key" > .env
echo "HUBSPOT_API_KEY=your_api_key" >> .env
Step 2: Utility Functions
Create a file named utils.mjs in the src folder and add the following utility functions:
import fs from "fs";
import {parseString} from "@fast-csv/parse";
/*
Load HubSpot tickets from a CSV file
@param {string} [filePath] - The file path to the CSV file
@return {Promise<object[]>} - The list of tickets from the CSV file
*/
export const loadTicketsFromCsv = (filePath) => new Promise((resolve, reject) => {
if (!filePath) {
filePath = "tickets.csv";
}
const csvString = fs.readFileSync(filePath, "utf8");
const tickets = [];
parseString(csvString, {
headers: (headers) => {
headers.map((header, index, arr) => {
if (arr.indexOf(header) !== index) {
arr[index] = `${header}_${arr.filter((h) => h === header).length}`;
}
});
return headers;
}
})
.on("data", (data) => tickets.push(data))
.on("error", (error) => reject(error))
.on("end", () => resolve(tickets));
});
/*
Save data to a JSON file
@param {object} data - The data to save
@param {string} [filePath] - The file path to save the data
@return {Promise<string>} - The file path where the data was saved
*/
export const saveJsonToFile = async (data, filePath) => {
if (!filePath) {
filePath = "output.json";
}
if (!data) {
throw new Error("No data provided to saveJsonToFile");
}
await fs.promises.writeFile(filePath, JSON.stringify(data, null, 2));
console.log(`Data saved to ${filePath}`);
return filePath;
};
Set Up HubSpot Utilities
Create a file named hs-utils.mj in the src folder and add the following HubSpot utility functions:
import {Client} from "@hubspot/api-client";
const getHubspotClient = async () => {
return new Client({accessToken: process.env.HUBSPOT_API_KEY});
};
/*
Get a list of tickets from HubSpot
@param {string} [ticketId] - The ticket ID to get
*/
export const getHubspotTicketById = async (ticketId) => {
const client = await getHubspotClient();
const ticket = await client.crm.objects.basicApi.getById(
'tickets',
ticketId,
undefined,
undefined,
['email', 'contact', 'company'],
);
return ticket;
};
/*
Get a list of emails by their IDs
@param {string[]} emailIds - The list of email IDs
@return {Promise<object[]>} - The list of emails object from HubSpot
*/
export const getHubspotEmailsByIds = async (emailIds) => {
if (!emailIds || emailIds.length === 0) {
return [];
}
// Initialize the HubSpot client
const client = await getHubspotClient();
// Get the emails
const emailProps = [
'hs_email_subject', 'hs_email_body', 'hs_internal_email_notes',
'hs_email_outcome', 'hs_attachment_ids', 'hs_meeting_body',
'hs_timestamp', 'hs_email_sent_time', 'hs_email_received_time',
'hs_email_status', "hs_email_text", "hs_email_direction"
];
const emails = await client.crm.objects.batchApi.read('emails', {
inputs: emailIds.map((id) => ({id})),
properties: emailProps,
});
return emails.results ?? [];
};
Implement Language Model Utilities
Create a file named lc-utils.mjs in the src folder and add the following language model utility functions:
import {z} from 'zod';
import {ChatAnthropic} from '@langchain/anthropic';
import {PromptTemplate} from '@langchain/core/prompts';
/*
Use LLM to pick the best category for a ticket
@param {string} ticketContextStr - The context of the ticket
@param {string[]} categoriesList - A list of categories to choose from
@param {string[]} questionsList - A list of questions to choose from
@return {Promise<{category: string, question: string}>} - The best category and question for the ticket
*/
export const categorize = async (ticketContextStr, categoriesList, questionsList) => {
const prompt = PromptTemplate.fromTemplate([
"You are a technical writer working at Autohost, a KYC and fraud detection company serving the short-term rental industry.",
"Consider the following support ticket context:",
"<ticket>",
"{ticket}",
"</ticket>",
"Also consider the following list of existing frequently asked questions (FAQ):",
"<questions>",
"{questions}",
"</questions>",
"Based on the context, select the best matching FAQ question or generate a new one.",
"Then, assign the ticket to one of the following categories:",
"{categories}",
].join("\n"));
const model = new ChatAnthropic({
modelName: 'claude-3-5-sonnet-20240620',
maxTokens: 4000,
});
const functionCallingModel = model.withStructuredOutput(z.object({
category: z.string({description: "The category assigned to the ticket"}),
question: z.string({description: "The question assigned to the ticket"}),
}));
const chain = prompt.pipe(functionCallingModel);
const response = await chain.invoke({
ticket: ticketContextStr,
questions: questionsList.map((question) => `- ${question}`).join("\n"),
categories: categoriesList.map((category) => `- ${category}`).join("\n"),
});
return response;
};
/*
Create or update an answer for a ticket question
@param {string} ticketContextStr - The context of the ticket
@param {string} question - The question to answer
@param {string} existingAnswerOrNull - The existing answer, if any
@return {Promise<string>} - The generated answer for the question
*/
export const createOrUpdateAnswer = async (ticketContextStr, question, existingAnswerOrNull) => {
const prompt = PromptTemplate.fromTemplate([
"You are a technical writer working at Autohost, a KYC and fraud detection company serving the short-term rental industry.",
"Consider the following ticket context:",
"<ticket>",
"{ticket}",
"</ticket>",
"Consider the following question:",
"<question>",
"{question}",
"</question>",
"Consider the existing answer (if any) when generating the new answer:",
"<answer>",
"{answer}",
"</answer>",
"",
"Please write an FAQ article to the question based on the context.",
"",
"Rules you must follow:",
"- If an answer already exists, update the existing answer with the new information.",
"- The answer should be clear, concise, and relevant to the context.",
"- The answer should be formatted as an FAQ article for product documentation.",
"- When you do not have enough information to answer the question, return \"Not enough information to answer the question.\" - THIS IS IMPORTANT!",
"",
"I will give you a $200 bonus if you can provide a high-quality answer.",
].join("\n"));
const model = new ChatAnthropic({
modelName: 'claude-3-5-sonnet-20240620',
maxTokens: 4000,
});
const functionCallingModel = model.withStructuredOutput(z.object({
answer: z.string({description: "The FAQ article that answers the question"}),
}));
const chain = prompt.pipe(functionCallingModel);
const response = await chain.invoke({
ticket: ticketContextStr,
question: question,
answer: existingAnswerOrNull ?? "",
});
const isNotEnoughInformation = response.answer.toLowerCase().includes("not enough information to answer the question");
if (isNotEnoughInformation && existingAnswerOrNull) {
response.answer = existingAnswerOrNull;
}
return response.answer;
};
Notice that in one of the prompts I'm offering a bonus for a high-quality answer. This is a fun way to encourage the AI to generate better responses. A study in 2023 showed that AI models perform better when they are incentivized with rewards.
Create In-Memory Database
Create a file named memdb.mjs in the src folder to manage the knowledge base items:
import fs from "fs";
export const db = {
qa_items: new Set(),
categories: [
"Reservation",
"Listings",
"Buildings",
"Activity Log",
"Analytics",
"Screening Assistant",
"Guest Portal",
"Settings",
"Accounts",
"Billing"
]
};
/*
Initialize the database from a JSON file
@return {Promise<void>}
*/
export const initDB = async () => {
try {
const data = JSON.parse(fs.readFileSync("output.json", "utf8"));
db.qa_items = new Set(data);
} catch (error) {
console.error("Error initializing database:", error.message);
}
};
/*
Add an item to the Set of items in the database
The counter is optional and defaults to 1
@param {string} category - The category of the item
@param {string} question - The question of the item
@param {string} answer - The answer of the item
@param {number} [counter=1] - The counter of the item
@return {void}
*/
export const addItemToDB = (category, question, answer, counter) => {
if (!category || !question || !answer) {
throw new Error("Invalid item");
}
// Find existing item
const existingItem = [...db.qa_items].find((item) => item.question.toLowerCase() === question.toLowerCase());
// Create an updated item
const newItem = {
category: category,
question: question,
answer: answer,
counter: counter ?? (existingItem ? existingItem.counter + 1 : 1),
};
// Remove the existing item
if (existingItem) {
db.qa_items.delete(existingItem);
}
// Add the new item
db.qa_items.add(newItem);
};
Remember to change the categories list to match your existing documentation categories.
Implement Main Processing Logic
Create a file named main.mjs in the src folder to orchestrate the ticket processing workflow:
import {getHubspotTicketById, getHubspotEmailsByIds} from "./hs-utils.mjs";
import {categorize, createOrUpdateAnswer} from "./lc-utils.mjs";
import {addItemToDB, initDB, db} from "./memdb.mjs";
import {loadTicketsFromCsv, saveJsonToFile} from "./utils.mjs";
/*
Process a ticket from HubSpot
@param {object} ticket - The ticket object from HubSpot CSV
@return {Promise<void>}
*/
const processTicket = async (ticket) => {
// Skip tickets without a classification
if (!ticket['Category']) {
console.log(`Skipping ticket without category: ${ticket['Ticket ID']} (${ticket['Ticket name']})`);
return;
}
// Skip tickets that are not "General inquiry", "Account Inquiry (CS)", or "Product Issue (Dev)"
//
// (You should customize this list to match your ticket categories)
//
if (!["General inquiry", "Account Inquiry (CS)", "Product Issue (Dev)", ""].includes(ticket['Category'].trim())) {
console.log(`Skipping ticket that does not match category: ${ticket['Ticket ID']} (${ticket['Ticket name']})`);
return;
}
// Skip tickets that are not in the "Closed" stage
if (!ticket['Ticket status'].toLowerCase().includes("closed")) {
console.log(`Skipping ticket that is not closed: ${ticket['Ticket ID']} (${ticket['Ticket name']})`);
return;
}
// Get the ticket from HubSpot
const hubspotTicket = await getHubspotTicketById(ticket['Ticket ID'], {
properties: ["subject", "content", "hs_pipeline", "hs_pipeline_stage"],
});
// Get the email IDs associated with the ticket
const emailIds = (((hubspotTicket.associations || {}).emails || {}).results || []).map((email) => email.id);
if (!emailIds || emailIds.length === 0) {
console.warn(`No emails found for ticket: ${ticket['Ticket ID']} (${ticket['Ticket name']})`);
return;
}
// Fetch the email objects from HubSpot
const emails = await getHubspotEmailsByIds(emailIds);
// Extract the email content
const emailsContext = emails.map((email) => {
email.properties.hs_email_text = email.properties.hs_email_text.replace(/\[cid:[a-f0-9-]+\]/g, "");
const text = [
"<email>",
`Date: ${(email.properties.hs_email_received_time || email.properties.hs_email_sent_time || email.properties.hs_timestamp).split("T")[0]}`,
`Subject: ${email.properties.hs_email_subject}`,
'',
`${email.properties.hs_email_text}`,
"</email>",
].join("\n");
return text;
}).join("\n");
// Create the LLM context for the ticket
const context = [
`Ticket classification: ${ticket['Category']}`,
`Ticket title: ${ticket['Ticket name']}`,
`Ticket emails:\n${emailsContext}`,
].join("\n");
// Create a list of all existing questions in the database
const questions = [...db.qa_items].map((item) => item.question);
// Get the best category and question for the ticket
const {category, question} = await categorize(
context,
db.categories,
questions
);
// Check if the category and question are valid
if (!category || !question) {
console.warn(`Could not categorize ticket: ${ticket['Ticket ID']} (${ticket['Ticket name']})`);
return;
}
// Find the category in the database
const categoryItem = db.categories.find((item) => item.toLowerCase() === category.toLowerCase());
if (!categoryItem) {
console.warn(`Category "${category}" not found for ticket: ${ticket['Ticket ID']} (${ticket['Ticket name']})`);
return;
}
// Find the question in the database
const faqItem = [...db.qa_items].find((item) => item.question.toLowerCase() === question.toLowerCase());
// Create or update answer in the database
const answer = await createOrUpdateAnswer(context, question, faqItem?.answer);
// Add or update the question and answer in the database
addItemToDB(category, question, answer);
// Save the updated database
await saveJsonToFile([...db.qa_items]);
};
/*
Main function to process HubSpot tickets from a CSV file
@param {string} csvFilePath - The file path to the CSV file
@return {Promise<void>}
*/
export const main = async (csvFilePath) => {
// Initialize the database
await initDB();
console.log(`Loaded ${db.qa_items.size} items from the database`);
if (db.qa_items.size === 0) {
console.warn("The database is empty. Please add items to the database before running the script.");
return;
}
// Load the CSV file
const tickets = await loadTicketsFromCsv(csvFilePath);
const totalTickets = tickets.length;
let processedTickets = 0;
console.log(`Loaded ${totalTickets} tickets from HubSpot`);
// Process each ticket
for (const ticket of tickets) {
const progress = Math.round((processedTickets / totalTickets) * 100);
try {
await processTicket(ticket);
} catch (error) {
console.error(`Error processing ticket: ${ticket['Ticket ID']} (${ticket['Ticket name']})`);
console.error(error);
}
console.log(`Processed ${processedTickets} of ${totalTickets} tickets (${progress}%)`);
processedTickets++;
}
};
Create Entry Point
Create a file named index.mjs in the project root to run the main script:
import "dotenv/config";
import {join} from "node:path";
import {main} from "./src/main.mjs";
// Run the main function
(async () => {
const filePath = join(process.cwd(), "tickets.csv");
await main(filePath);
})();
Add JSON to CSV Converter
Create a file named json2csv.mjs in the project root to convert the generated JSON file to a CSV:
import fs from 'fs';
import {format} from '@fast-csv/format';
const csvStream = format({headers: true});
const jsonData = fs.readFileSync('output.json', 'utf8');
const data = JSON.parse(jsonData);
csvStream
.pipe(fs.createWriteStream('output.csv'))
.on('end', () => console.log('Done writing.'));
data.forEach((row) => {
csvStream.write(row);
});
csvStream.end();
That's it! You've set up the project and implemented the main processing logic to generate a knowledge base from support tickets on HubSpot using AI. Let's run the script and see it in action.
Usage
Step 1: Export HubSpot Tickets
Use this guide to export tickets from HubSpot.
Then, save the exported CSV file as tickets.csv in the project directory.
Step 2: Run the Script
Run the main script to process tickets and generate the knowledge base:
node index.mjs
This will take a while depending on the number of tickets you have.
Step 3: Convert JSON to CSV
Convert the generated JSON file to a CSV file for easy viewing:
node json2csv.mjs
You can now view the generated knowledge base in the output.csv file.
Conclusion
In this article, we've explored how to use AI to create a knowledge base from support tickets on HubSpot. By automating the process of categorizing tickets and generating FAQ articles, you can save time and resources while ensuring that your documentation is always up-to-date. This approach can help you provide better support to your customers and improve the overall customer experience.